三十功名尘与土
八千里路云和月
关于leveldb的整体思路,已经有超级多的博客讲过了,这里我只是浏览了很多资料,然后综合一下,做一个易理解的阐述。
数据接口
leveldb的接口十分简单,对于用户来说其实就是只有几个。
static Status Open(const Options& options,
const std::string& name,
DB** dbptr);
DB() { }
virtual ~DB();
// Set the database entry for "key" to "value". Returns OK on success,
// and a non-OK status on error.
// Note: consider setting options.sync = true.
virtual Status Put(const WriteOptions& options,
const Slice& key,
const Slice& value) = 0;
// Remove the database entry (if any) for "key". Returns OK on
// success, and a non-OK status on error. It is not an error if "key"
// did not exist in the database.
// Note: consider setting options.sync = true.
virtual Status Delete(const WriteOptions& options, const Slice& key) = 0;
// Apply the specified updates to the database.
// Returns OK on success, non-OK on failure.
// Note: consider setting options.sync = true.
virtual Status Write(const WriteOptions& options, WriteBatch* updates) = 0;
// May return some other Status on an error.
virtual Status Get(const ReadOptions& options,
const Slice& key, std::string* value) = 0;
这几个接口的作用是显而易见的,分别对应了
- Put:写入单个键值对,其实最后调用的还是Write
- Delete:根据给的键值进行删除
- Write:写入多个键值对,相当于多次Put
- Get:根据给的键,读取对应的值
也就是我们常说的“增删改查”。
这里要说明的是,Put和Write的最大区别在于,Write写入多项数据,只有一项未成功,就不会写入,就是要么都成功,要么都失败,而Put仅是单项写入。可以看到,其实Write是包含了Put的功能的,所以Put实际上最后也是调的Write。
leveldb设计解决什么问题?
从上述四个“增删改查”的接口来看,其实不难,其实几百行代码就能解决,为什么leveldb会写出上万行代码呢?
如果要完成一个单机版的kv存储引擎,考虑需要解决以下几个问题:
- 不能把所有数据都存入内存,需要将内存中数据同步到磁盘上
- 内存存不下那么多数据
- 断电后,内存中数据就丢失了,不能持久化存储
- 如果将数据存储到磁盘上,怎么解决磁盘读取速度慢的问题?
- 磁盘的随机读写速度要慢于顺序读写,怎么利用这点呢?
为了解决这三个问题,leveldb做了什么事情?
leveldb的设计
leveldb首先是把数据写入到内存中,当然是以WAL的方式写入,在硬盘上存储为SST文件,划分为不同的Level,Level0的文件由Memtable直接Dump产生,其他Level的SST文件则由上一层归并产生。
Memtable
Memtable对应leveldb暂存在内存中的数据,无论是读还是写,都会先访问内存中的数据。
Memtable的实现有如下特点:
- 常驻内存
- 使用跳表实现
- 支持阻写状态下的遍历操作
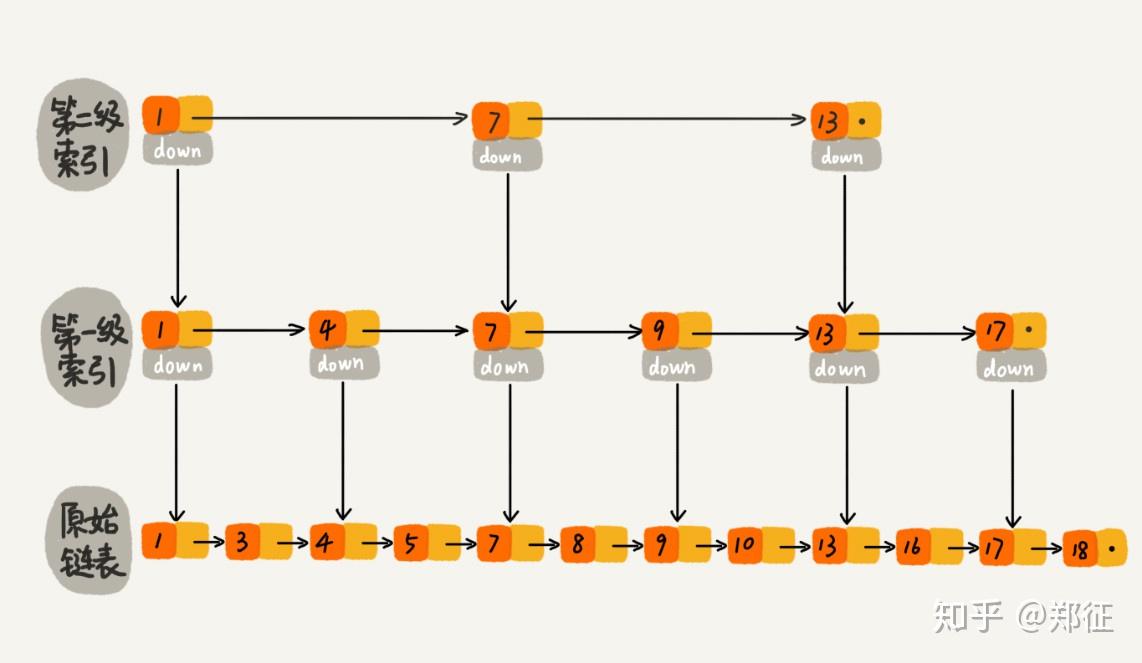
跳表基于链表实现:
Log
数据写入Memtable之前,都会先写入Log,以免数据丢失。leveldb启动的时候会从log中回复Memtable的内容,所以Log模块得实现以下需求:
- 磁盘存储
- 大量的Append操作
- 没有删除单条数据的操作
- 遍历的读操作
Log文件划分为固定长度的Block,每个BLock包含多个Record;Record分为Record头和内容,Record头中记录了长度和校验码等信息。
SST文件
leveldb中把SST文件定义成Table,每个Table又划分为多个连续的Block,每个Block中又存储多条Entry:

磁盘上的block根据新旧先后分层。总是上面一层的与下面一层的合并。好吧,这里先不多说了,现在也不了解,先知道有这么个东西。
总结
总结上面说的,基本就是以下的思路:
- 写WAL LOG,也就是先写日志
- 日志写完后,更新内存,g也就是Memtable
- 当内存中存储的数据达到一定的量以后,就把Memtable变成不可变的内存块(方便和磁盘上的块合并)
- 把内存块上与磁盘上的Block,也就是.sst文件进行合并,到这里内存和磁盘上块的合并是顺序读写的
- 磁盘上的Block根据新旧先后分层,总是上一层与下一层合并
- 读的时候先查内存,内存中没有的时候,再顺次从Leve0~LevelN里面的磁盘查找,直到找到对应的Key,不存在则返回NULL
