云想衣裳花相容
春风拂槛露华浓
对子进程进行profile,使用到了libunwind库中的几个接口,但发现耗费时间颇多。然后一个点一个点的排查,居然是unw_get_proc_name和unw_step两个最频繁调用的接口耗费时间最多。
初探libunwind性能
简单地写了几行代码,对系统中某个后台进程trace。
选择的进程就是下面这个,fcitx,随便选的,我也不知道它干嘛的。

然后麻利地写好trace程序:
#include <libunwind-ptrace.h>
#include <libunwind.h>
#include <libunwind-x86_64.h>
#include <cstdio>
#include <cstdlib>
#include <sys/ptrace.h>
#include <unistd.h>
#include <string>
#include <chrono>
using hrs = std::chrono::high_resolution_clock;
using ms = std::chrono::microseconds;
unw_addr_space_t as;
void *context = nullptr;
hrs::time_point t1, t2, t3;
long caltime(hrs::time_point t1, hrs::time_point t2) {
return std::chrono::duration_cast<ms>(t2 - t1).count();
}
using namespace std;
void die(string msg) {
printf("%s\n", msg.c_str());
exit(1);
}
long back(pid_t pid) {
long steptime = 0;
long ret = ptrace(PTRACE_ATTACH, pid, nullptr, nullptr);
if (ret != 0)
die("ERROR: cannot attach\n");
usleep(1000);
unw_cursor_t cursor;
if (unw_init_remote(&cursor, as, context) != 0)
die("ERROR: cannot initialize cursor for remote unwinding\n");
do {
unw_word_t offset, pc;
char sym[4096];
if (unw_get_reg(&cursor, UNW_REG_IP, &pc))
die("ERROR: cannot read program counter\n");
printf("0x%lx: ", pc);
t1 = hrs::now();
if (unw_get_proc_name(&cursor, sym, sizeof(sym), &offset) == 0)
printf("(%s+0x%lx)\n", sym, offset);
else
printf("-- no symbol name found\n");
t2 = hrs::now();
ret = unw_step(&cursor);
t3 = hrs::now();
printf("proc_name:%ld, step:%ld, ret:%d\n", caltime(t1, t2), caltime(t2, t3), ret);
if (pc)
steptime += caltime(t2, t3);
} while (ret > 0);
(void) ptrace(PTRACE_DETACH, pid, 0, 0);
return steptime;
}
int main(int argc, char **argv) {
as = unw_create_addr_space(&_UPT_accessors, 0);
pid_t pid = 4508;
context = _UPT_create(pid);
for (int i = 0; i < 1; i++) {
long time = back(pid);
printf("\ntime:%ld\n\n", time);
sleep(1);
}
_UPT_destroy(context);
return 0;
}
然后打印结果:
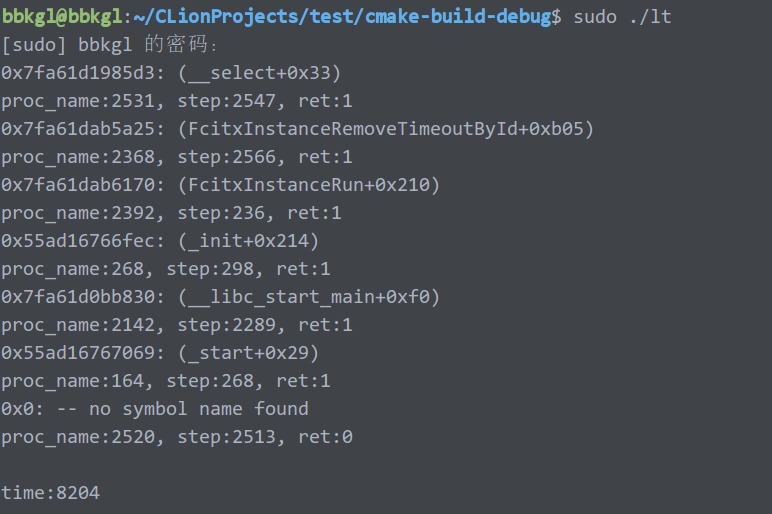
恐怖故事发生了!!!
unw_get_pro_name随随便便就2-3ms了,unw_step也是开开心心就2-3ms了!!!!
统计了trace中unw_step的总时间,是8204us。
我是觉得很恐怖的,如果用libunwind来做profiler,这个时间显然是不能接受的。
使用unw_set_caching_policy
其实在官方文档中有关于unw_set_caching_policy的介绍,其中写明remote默认是不能用unw_set_caching_policy的。

To speed up execution,
libunwindmay aggressively cache the information it needs to perform unwinding. If a process changes during its lifetime, this creates a risk oflibunwindusing stale data. For example, this would happen iflibunwindwere to cache information about a shared library which later on gets unloaded (e.g., via dlclose(3)).To prevent the risk of using stale data,
libunwindprovides two facilities: first, it is possible to flush the cached information associated with a specific address range in the target process (or the entire address space, if desired). This functionality is provided by unw_flush_cache(). The second facility is provided by unw_set_caching_policy(), which lets a program select the exact caching policy in use for a given address-space object. In particular, by selecting the policyUNW_CACHE_NONE, it is possible to turn off caching completely, therefore eliminating the risk of stale data alltogether (at the cost of slower execution). *By default, caching is enabled for local unwinding only. **The cache size can be dynamically changed with *unw_set_cache_size(), which also fluches the current cache. *
简单翻译一下:
为了加速执行,
libunwind可能会主动地将unwind所需要的一些信息缓存起来。如果一个进程在其生命周期里发生了某些改变,会导致libunwind使用过时数据的风险。举个例子,当libunwind已经缓存了某个共享库的一些信息,但这个共享库随后发生了改变,那缓存的数据就是过时的。为了防止使用过时数据的风险,
libunwind提供了两个方法:1.可以在目标进程中刷新与特定地址范围(或整个地址空间,如果需要)关联的缓存信息。这个方法对应的接口就是 unw_flush_cache()。2.第二种方法对应的接口是unw_set_caching_policy(),通过它可以选择用于给定地址空间对象的缓存策略。特别是,通过选择策略“ UNW_CACHE_NONE”,可以完全关闭缓存,从而消除了使用过时数据的风险(以执行速度较慢为代价)。默认情况下,该cache策略只对本地的堆栈展开起作用。cache的大小可以由 unw_set_cache_size()动态地指定,同时也会刷新缓冲区。
言外之意,remote的trace需要手动打开cache,不然会很慢?
这里先做个推测,假设这个cache对于remote的trace是默认不打开的,所以导致remote会明显地慢。
接下来验证这点,如果推测正确的话,unw_set_caching_policy()是可以用于remote的trace的,而且会显著加快速度。
所以存在两种情况,使用unw_set_caching_policy()后的速度和不使用的速度对比。
开启cache
直接在之前的代码里加入unw_set_caching_policy(),并设置全局cache。
为了确定是cache起作用,将循环trace5次,对比每次的时间。
#include <libunwind-ptrace.h>
#include <libunwind.h>
#include <libunwind-x86_64.h>
#include <cstdio>
#include <cstdlib>
#include <sys/ptrace.h>
#include <unistd.h>
#include <string>
#include <chrono>
using hrs = std::chrono::high_resolution_clock;
using ms = std::chrono::microseconds;
unw_addr_space_t as;
void *context = nullptr;
hrs::time_point t1, t2, t3;
long caltime(hrs::time_point t1, hrs::time_point t2) {
return std::chrono::duration_cast<ms>(t2 - t1).count();
}
using namespace std;
void die(string msg) {
printf("%s\n", msg.c_str());
exit(1);
}
long back(pid_t pid) {
long steptime = 0;
long ret = ptrace(PTRACE_ATTACH, pid, nullptr, nullptr);
if (ret != 0)
die("ERROR: cannot attach\n");
usleep(1000);
unw_cursor_t cursor;
if (unw_init_remote(&cursor, as, context) != 0)
die("ERROR: cannot initialize cursor for remote unwinding\n");
do {
unw_word_t offset, pc;
char sym[4096];
if (unw_get_reg(&cursor, UNW_REG_IP, &pc))
die("ERROR: cannot read program counter\n");
printf("0x%lx: ", pc);
t1 = hrs::now();
if (unw_get_proc_name(&cursor, sym, sizeof(sym), &offset) == 0)
printf("(%s+0x%lx)\n", sym, offset);
else
printf("-- no symbol name found\n");
t2 = hrs::now();
ret = unw_step(&cursor);
t3 = hrs::now();
printf("proc_name:%ld, step:%ld, ret:%d\n", caltime(t1, t2), caltime(t2, t3), ret);
if (pc)
steptime += caltime(t2, t3);
} while (ret > 0);
(void) ptrace(PTRACE_DETACH, pid, 0, 0);
return steptime;
}
int main(int argc, char **argv) {
as = unw_create_addr_space(&_UPT_accessors, 0);
unw_set_caching_policy(as, UNW_CACHE_GLOBAL);
pid_t pid = 4508;
context = _UPT_create(pid);
for (int i = 0; i < 5; i++) {
long time = back(pid);
printf("\ntime:%ld\n\n", time);
sleep(1);
}
_UPT_destroy(context);
return 0;
}
以下5张图代表循环5次trace的打印结果:
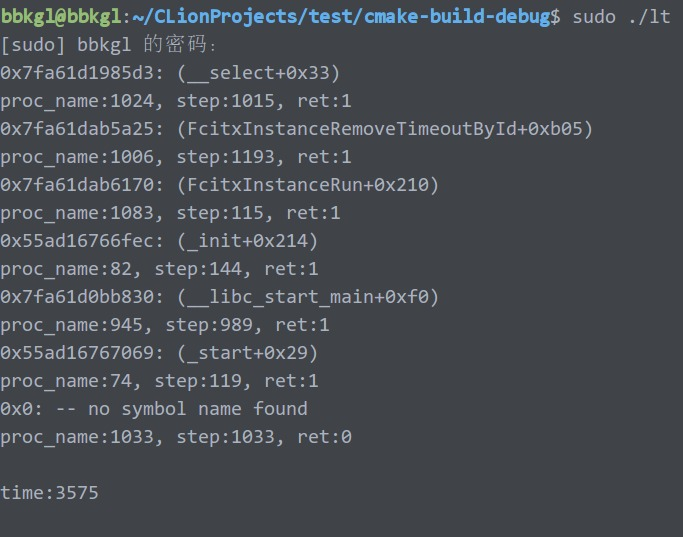

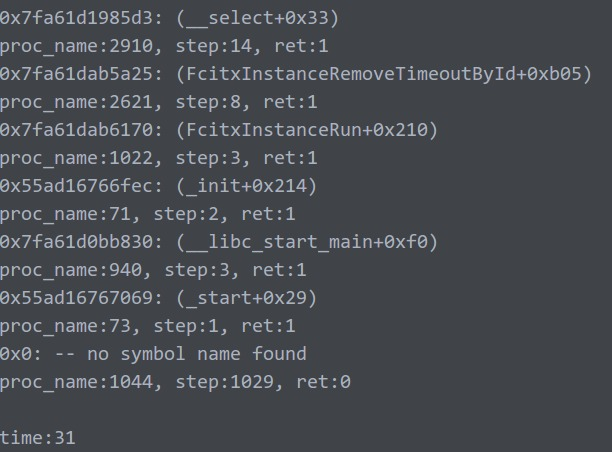
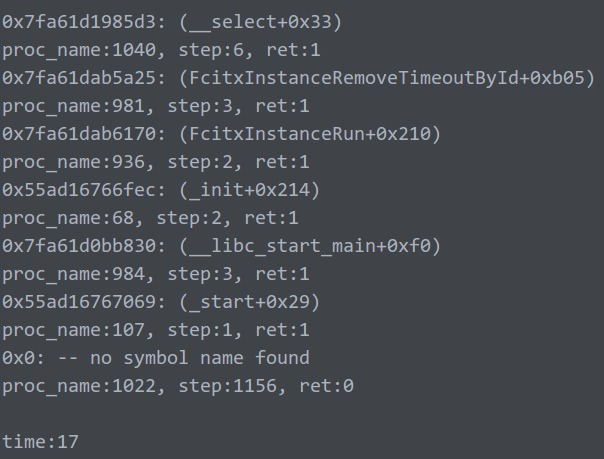
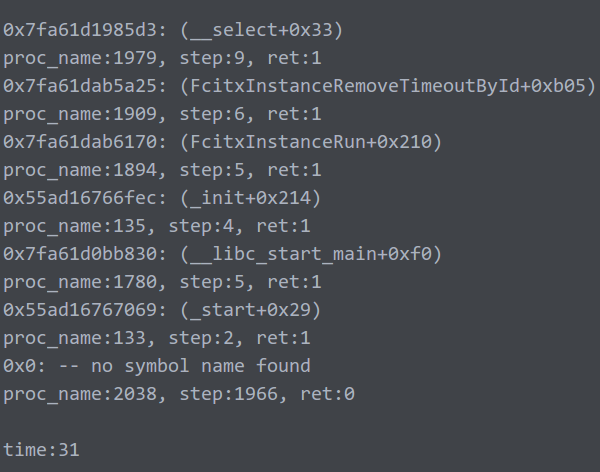
结果非常符合我的推测!!!
第一张图对比后面4张图,百倍的提升好吧!!!
不多说,unw_step()的时间直接从几百上千到了个位数2333。
注:最后一次的no symbol不做统计,没意义。
不开cache
不开的话,直接把unw_set_caching_policy(as, UNW_CACHE_GLOBAL);给注释掉。
#include <libunwind-ptrace.h>
#include <libunwind.h>
#include <libunwind-x86_64.h>
#include <cstdio>
#include <cstdlib>
#include <sys/ptrace.h>
#include <unistd.h>
#include <string>
#include <chrono>
using hrs = std::chrono::high_resolution_clock;
using ms = std::chrono::microseconds;
unw_addr_space_t as;
void *context = nullptr;
hrs::time_point t1, t2, t3;
long caltime(hrs::time_point t1, hrs::time_point t2) {
return std::chrono::duration_cast<ms>(t2 - t1).count();
}
using namespace std;
void die(string msg) {
printf("%s\n", msg.c_str());
exit(1);
}
long back(pid_t pid) {
long steptime = 0;
long ret = ptrace(PTRACE_ATTACH, pid, nullptr, nullptr);
if (ret != 0)
die("ERROR: cannot attach\n");
usleep(1000);
unw_cursor_t cursor;
if (unw_init_remote(&cursor, as, context) != 0)
die("ERROR: cannot initialize cursor for remote unwinding\n");
do {
unw_word_t offset, pc;
char sym[4096];
if (unw_get_reg(&cursor, UNW_REG_IP, &pc))
die("ERROR: cannot read program counter\n");
printf("0x%lx: ", pc);
t1 = hrs::now();
if (unw_get_proc_name(&cursor, sym, sizeof(sym), &offset) == 0)
printf("(%s+0x%lx)\n", sym, offset);
else
printf("-- no symbol name found\n");
t2 = hrs::now();
ret = unw_step(&cursor);
t3 = hrs::now();
printf("proc_name:%ld, step:%ld, ret:%d\n", caltime(t1, t2), caltime(t2, t3), ret);
if (pc)
steptime += caltime(t2, t3);
} while (ret > 0);
(void) ptrace(PTRACE_DETACH, pid, 0, 0);
return steptime;
}
int main(int argc, char **argv) {
as = unw_create_addr_space(&_UPT_accessors, 0);
// unw_set_caching_policy(as, UNW_CACHE_GLOBAL);
pid_t pid = 4508;
context = _UPT_create(pid);
for (int i = 0; i < 5; i++) {
long time = back(pid);
printf("\ntime:%ld\n\n", time);
sleep(1);
}
_UPT_destroy(context);
return 0;
}
只贴前两次的了,五个贴起来太累了。
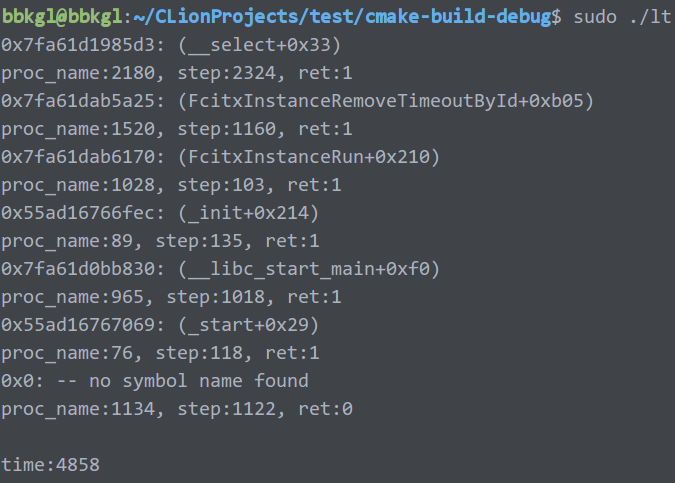
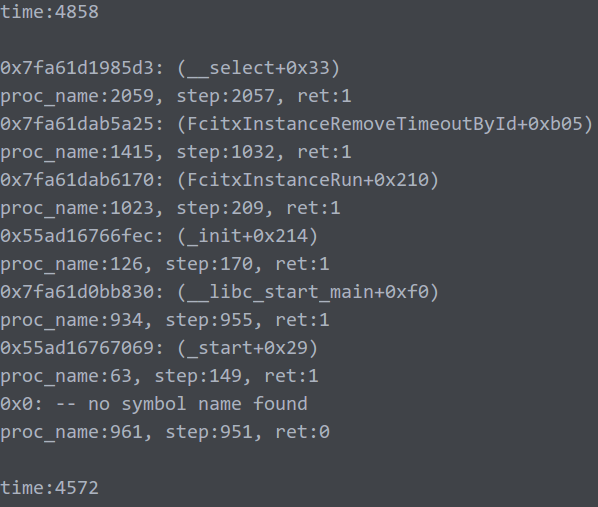
然后分别五次unw_step的时间分别是4858、4572、4597、4744、4677.
可以看到,五次时间差不多,都是4500us以上。
验证cache的功能
前面测试的其实都是同样的堆栈,也就是函数调用都是同样的,这里我自己写了一个随机调用函数的情况。
给出被trace的程序:
#include <cstdio>
#include <iostream>
#include <unistd.h>
#include <random>
using namespace std;
void f3(int);
void f1(int n) {
if (n == 0) {
printf("%d\n", getpid());
usleep(10 * 1000);
} else f1(n - 1);
}
void f2(int n) {
if (n == 0) {
usleep(10 * 1000);
} else f3(n - 1);
}
void f3(int n) {
if (n == 0) {
usleep(10 * 1000);
} else f2(n - 1);
}
int main() {
std::default_random_engine e;
while (true) {
int rd = e();
if (rd % 3 == 0)
f1(2);
else if (rd % 3 == 1)
f2(2);
else
f3(2);
}
return 0;
}
trace后的结果:
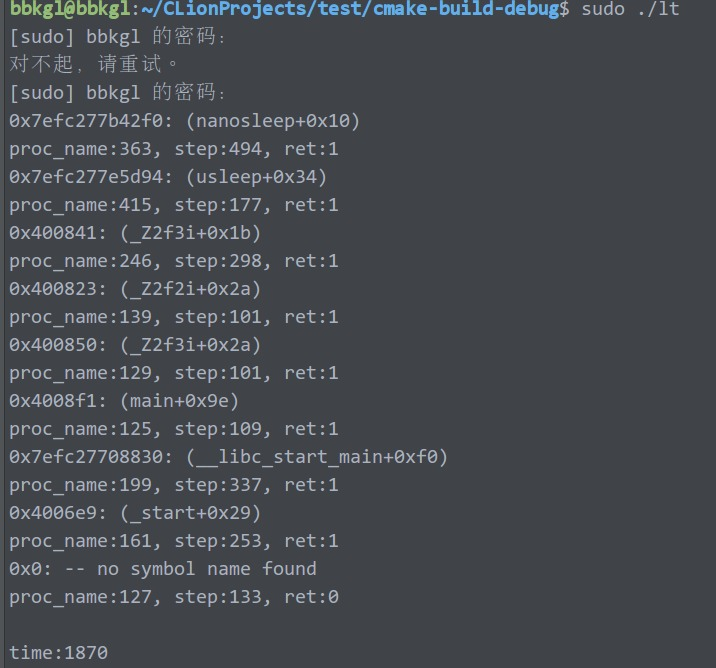

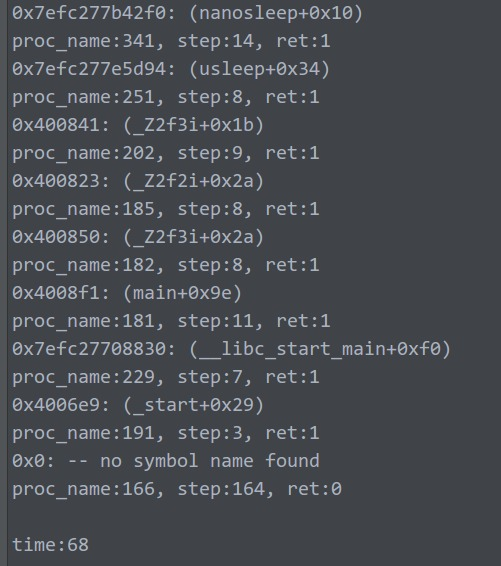
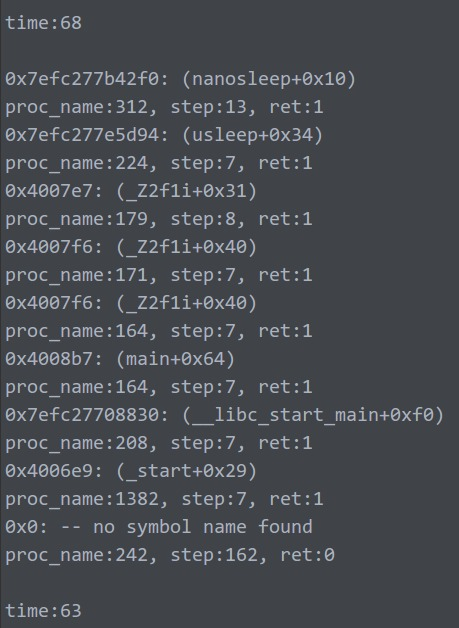
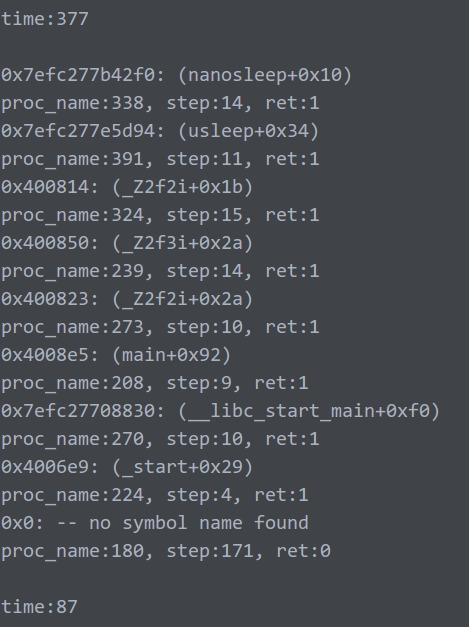
可以明显的看到,堆栈输出是正确且非重复的。
基本说明,这才是正确使用方法!
结论
unw_set_caching_policy会打开缓存,避免unw_step重复获取信息,所以大幅提升速度!
官网中说到的By default, caching is enabled for local unwinding only.。意思应该是,只有本地展开堆栈的时候默认开启(remote需要手动),而不是默认情况下只能local模式开启2333。。。