绿竹入幽径
青萝拂行衣
前面已经讲了大概的背景,以及如何自定义分配内存的地址,这里会讲luajit的大内存patch是如何利用这点而做到扩展可用内存到4GB的。
首先大概的阅读可以发现,luajit在给部分gc对象分配内存的时候,调用的是lj_alloc_create,这里面不用malloc,而是用mmap,mmap有个标志位MAP_32BIT,这样就会把内存分配在前32位的地址范围里。
而这个patch就是利用这点,把mmap又封了一层,在必要时候不用标志位MAP_32BIT,调的是系统的mmap64这个函数,且把标志位MAP_32BIT给去掉了。
这里的men在需要分配2GB以上时不为空,mmap64和mmap在64位中其实是一样的!所以区别就在mem这个里面了。
实际上调用mmap,如果第一个参数指定了,则会优先从这个地址开始分配虚拟内存空间,使用的标志位是MAP_PRIVATE | MAP_ANONYMOUS。
前面已经说明且验证过了如果指定第一个参数,且合适的话,就会直接在这个地址上进行内存分配!所以重点就变成了如何在复杂的内存空间里,找到这么一个合适的mem。。。
阅读代码发现,该patch基本算是自己去管理内存空间了,而不是让系统去管理。所以主要是两个关键问题:
- 整个堆内存是如何布局的?
- 用什么方法去管理碎片?
回答:
- 管理范围为初始的堆顶到最大的4GB,
- 静态链表,由低地址到髙地址
在初始条件下分配内存,都是从低地址到高地址寻找空闲空间来进行分配的,所以一开始,空闲的内存地址一定比已经分配的地址高。
堆内存布局
首先来看一段代码:
WrapMMAP *init_lowmem_mmap() {
uint8_t *start;
#if ENABLE_VERBOSE
atexit(dump_stats);
#endif
sys_pagesize = sysconf(_SC_PAGE_SIZE);
// 通过调用sbrk(0)的方式来获取当前堆结束地址,这里同时做了页对齐处理
/* find the end of the bss/brk segment (and make sure it is page-aligned). */
region_start = ((uint8_t *)(((ptrdiff_t)sbrk(0)) & ~(sys_pagesize - 1)) + sys_pagesize);
/* check if brk is inside the low 4Gbytes. */
// GCC6.3及以上版本中,可执行文件的堆顶地址几乎必大于4G
if(region_start > LOW_4G) {
/* brk is outside the low 4Gbytes, start managed region at lowest posible address */
region_start = (uint8_t *)sys_pagesize;
}
start = SYS_MMAP(region_start, sys_pagesize, PROT_NONE, M_FLAGS, -1, 0);
...
}
做了两件事
- 使用sbrk(0)获取到堆顶的地址
- 从堆顶选择一个符合分页对齐的地址给了region_start
这里的region_start其实是一个下界,是可分配堆内存的下界,而上界是哪里呢?4GB。
所以后续的内存管理都是在这个范围里的,即[region_start, 2^32]里进行管理。
静态链表
直接贴上数据结构定义直观一些2333,首先是数组/静态链表中每个结点的定义:
struct Segment {
seg_t start;
seg_t len;
seg_t prev;
seg_t next;
};
简单介绍下Segment,Segment用来管理一整块连续的内存,而静态链表则由多个Segment结点组成:
-
start,记录的是被管理内存的起始地址
-
len,是被管理内存的长度
-
prev,指向的是前一个结点在静态链表中的下标
-
next,指向的是下一个结点在静态链表中的下标
表示还是蛮清晰的。
然后是数组(作为静态链表的载体),这个静态链表就是为了方便管理这些Segment结点,为什么用静态链表呢?而不是直接用数组或者普通的链表。
-
首先每个结点都是有可能被增删的,且不是固定在尾部增删,不适合用数组
-
整个管理结点序列需要是有序的,即前结点管理的内存一定比后一个结点低,这样的调整不适合用数组
-
如果用普通动态申请的链表,不好管理内存,又得去管理动态链表结点的内存,就很麻烦
懂了吧!实际上有两个链表,后面会讲。
PageAlloc 结构体定义:
// free_list,已经启用,用来管理空间的Segment链表的表头节点,通常连续排列
// unused_list,还没有启用,但可能会启用的Segment链表的表头节点,通常是free_list中最大值+1
struct PageAlloc {
Segment *seg;
seg_t seg_len;
seg_t free_list; /* free memory list. */
seg_t unused_list; /* list of unused Segment structure. */
#if ENABLE_STATS
seg_t used_segs;
seg_t peak_used_segs;
#endif
};
注意到在PageAlloc的定义中有两个链表表头,分别是free_list和unused_list,这两个链表:
-
free_list:也就是已经被分配用来管理内存的Segment链表,里面管理的是所有空闲的内存,每一个结点则管理一块空闲内存,且每个结点按照start域从小到大排列
-
unused_list:还没有用来分配管理结点的链表头,里面的start域通常不是正常地址值
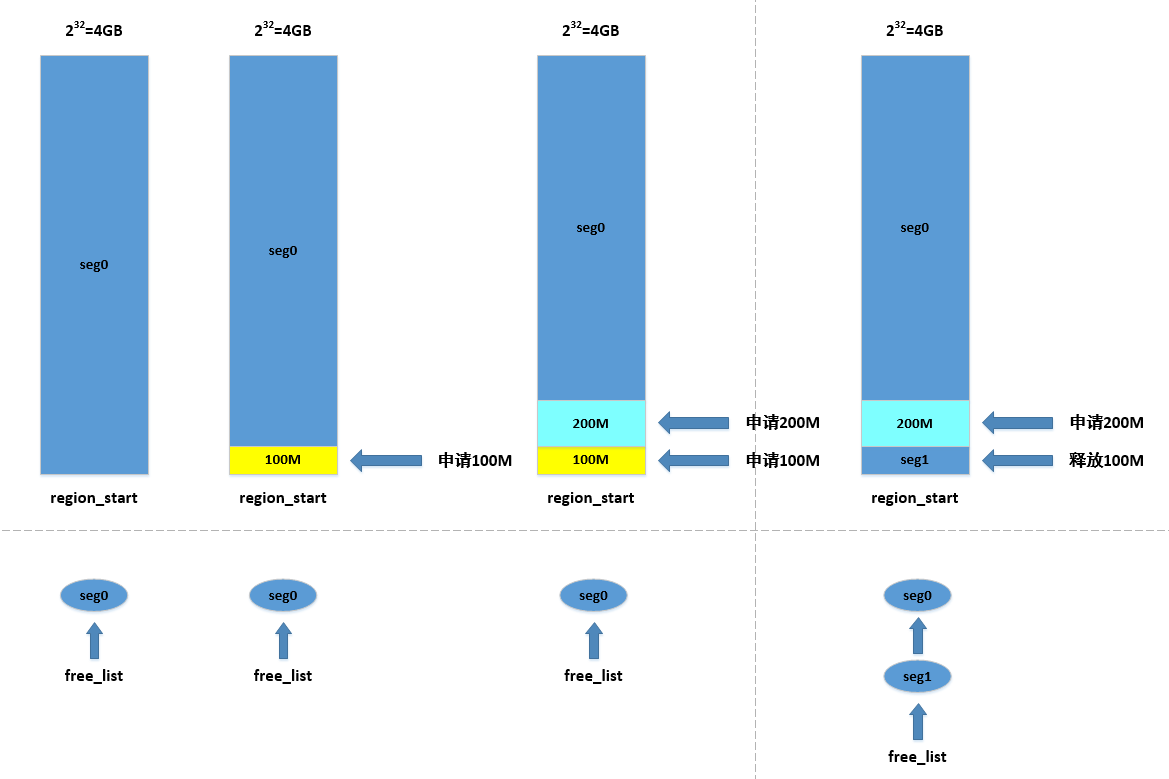
重点关注free_list,free_list就管理了[region_start, 2^32]范围所有里的内存块。
这里出现一个疑问?
空闲内存被管理了,那怎么管理不空闲(已经被分配的)内存呢?
答:插空!
实际上既然所有空闲内存都确定了,那不空闲也是确定的,两块相邻的空闲内存中间就是一块不空闲的内存。
于是内存管理的大问题就转化成了以下几个小问题:
-
如何保持链表free_list有序?有序是为了方便进行查找
-
内存的申请和释放对应free_list链表的删和增,怎么做增删?
-
如何给free_list添加新的管理结点?
这里简单写下回答,然后列出patch里具体的功能函数,当然实际上patch的方法也不是最优的解决方法,大家可以去参考:
-
保持free_list有序,这里说的有序实际上就是链表上前后两个结点满足a->start <= b->start的关系,然后主要是每次对结点进行操作的时候,都会考虑和前后结点满足上述关系,有两种约束:
a. 分配内存的时候,会依次从前往后寻找符合条件的Segment结点,这个时候实际上就是从低地址向高地址寻找的,实际分配内存时,保持前后结点的start域大小关系
b. 如果对应内存块长度大于需要的长度,则截断,返回的是低地址的内存首地址,这样使得已分配的是低地址,而空闲的是髙地址
-
申请内存对应的是Segment结点的删除和修改,首先寻找到地址值最低的空闲且长度合适的内存块进行分配,然后对链表的有序性进行维护,涉及到对每个Segment结点的处理,有两种情况,对应函数
page_alloc_get_segment()a. 如果这个内存块分配后还剩余,则结点继续存在
b. 如果内存块正好被分配完,这个对应的Segment结点就会被删除,被添加到unused_list里,并修改前后结点,就是类似链表的删除操作,对应函数
page_alloc_remove_seg() -
释放内存时,对应的是Segment结点的增加和合并,会直接寻找满足
addr + len == segnode->start的Segment结点segnode,然后会以[addr, addr + len]的范围新生成一个Segment结点,添加到free_list链表上,这里对应的函数函数page_alloc_release_segment和page_alloc_add_free_seg -
给free_list 添加新的结点可以分成两步:
a. 从unused_list那里直接拿,这里和前一个回答3里是一样的操作
b. unused_list需要扩充,对应的函数是
page_alloc_grow_list
总结
我感觉重要的内容就是这些,大内存patch的秘密基本都在这了,关于内存管理还有两个操作没讲了,就是指定内存地址对应的结点查找以及结点管理范围的分割,不过我发现汇编里根本没执行,就算了。当然这只是linux的,还有windows的,其实差不多,就是替换成windows里的mmap。
后面会画出出一个大概的图进行比较形象的解释。
读这种源码最大的障碍就是,读之前并不知道他的设计,而是通过源码去推测设计,比如这次patch内存的管理布局,读了才知道是这么搞的;再比如luajit中内存布局,之前也不知道是一堆TValue堆成的,但每读一次,提升都蛮大的。