今人不见古时月
今月曾经照古人
每一个lab都有大量的翻译文章和博客,然后对于这些文章中我认为比较重要的以及没有说清楚的部分进行补充和说明。
Part 1: PC Bootstrap
这里必须说以下CS和IP,这两个都是寄存器。
CS是代码段寄存器,IP是指令指针寄存器(相当于偏移地址)。修改CS、IP的指令不同于修改通用的寄存器值的指令,修改通用寄存器的值可以用mov 指令(mav ax,123),mov指令被称为传送指令。修改CS、IP的指令是jmp指令。jmp指令被称为转移指令。
修改这两个寄存器以后就能够让CPU执行对应位置的指令。
其中对应指令地址的计算为(段地址*16+偏移地址)合成物理地址,所以也就是CS * 16 + IP。
这也是为什么我们会看到gdb中的第一条指令[f000:fff0] 0xffff0: ljmp ....:
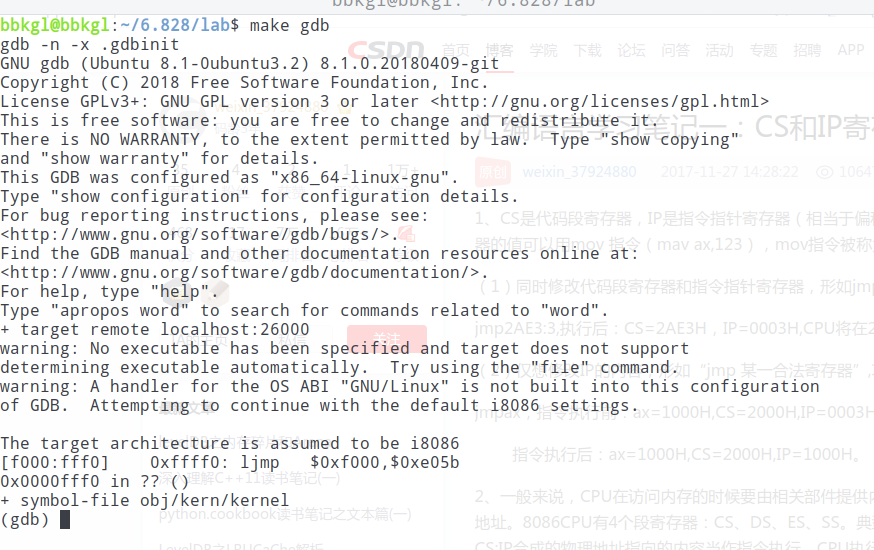
这是将要执行的第一条指令, 实际上符合0xffff0 = 0xf000 * 16 + 0xfff0 (实模式)。
Part 2: The Boot Loader
引导扇区
很多文章直接跳过引导扇区的部分,直接到了0000:7c00,让我很是懵逼,这里就多说一下。
对于PC来说,一个扇区就是512字节,如果有一个磁盘的第一个扇区是用来引导启动OS的(最后两个字节的内容是0x55AA),那么就把这个磁盘叫做启动盘,这个扇区就做启动扇区。在BIOS程序启动后,这个扇区的512字节的内容,就会被加载到0x7c00~0x7dff这个区域内。随后控制权就会交给引导程序,也就是我们这门课讲到的bootloader。
如何保证我们的引导程序boot.S/main.c是512字节并以0x55AA结尾呢?
可以看下perl脚本文件boot/sign.pl。
boot.S:进入保护模式并加载C程序
这里主要参考MIT6.828 Lab1:第2部分 The Boot Loader,已经说的很详细了。
可以在两个终端中分别使用make qemu-gdb和make gdb启动gdb进行调试,并在0x7c00处打下断点b *0x7c00,然后执行continue/c就能直接到boot.S中进行调试。
使用x/30i 0x7c00就能看到汇编源码了,可以和boot.S中进行对比。
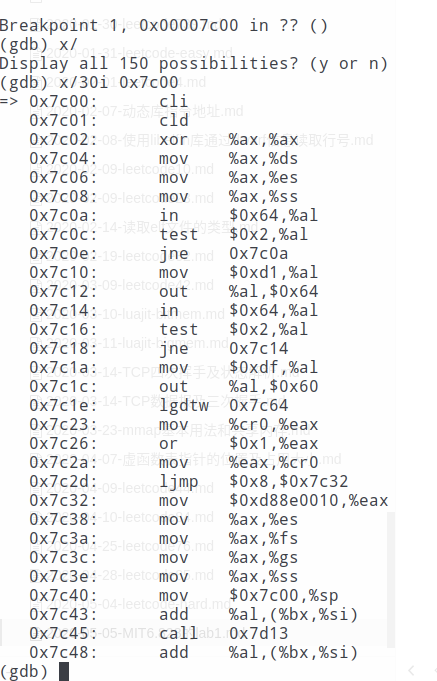
其中比较重要的就是:
- 加载全局描述符表,
lgdt这条指令的格式是lgdt m48操作数是一个48位的内存区域,该指令将这6字节加载到全局描述表寄存器(GDTR)中,低16位是全局描述符表(GDT)的界限值,高32位是GDT的基地址 - 从实模式进入保护模式,
lgdt指令后面的三行是将CR0寄存器第一位置为1,其他位保持不变,这将导致处理器的运行变成保护模式
下面捋一捋一些重要的背景和概念。
实模式
实模式下物理地址的计算就是物理地址 = 段基址 << 4 + 段内偏移,看上去麻烦点主要是因为早期CPU寄存器只有16位,只能寻址64KB,所有就用多个寄存器来进行寻址,也就是CS段寄存器和IP指令指针寄存器,不过现在64位的RIP已经没有不存在这个问题了吧。。。解决了寻址问题,但没解决安全问题,所以就有了下面的保护模式。。。
保护模式
前面是怎么进入保护模式的?
- 加载全局描述符表
- 打开CR0中的保护模式标志位。。。
进入保护模式后,最大最重要的区别就是CPU的寻址方式变化了,变成了繁琐的以下步骤,不变的是IP中存放的还是段偏移地址。
- 段寄存器现在存放的是段选择子(也就是段描述符的索引)
- CPU根据段选择子找到对应的段描述符
- 段描述符中记录着段基地址
- 根据之前的哪个公式
物理地址 = 段基址 << 4 + 段内偏移计算物理地址
为什么没有页表???
页表还没出生呐。。。
main.c:加载内核
先简单看下源码:
void bootmain(void) {
struct Proghdr *ph, *eph;
// read 1st page off disk
readseg((uint32_t) ELFHDR, SECTSIZE*8, 0);
// is this a valid ELF?
if (ELFHDR->e_magic != ELF_MAGIC)
goto bad;
// load each program segment (ignores ph flags)
ph = (struct Proghdr *) ((uint8_t *) ELFHDR + ELFHDR->e_phoff);
eph = ph + ELFHDR->e_phnum;
for (; ph < eph; ph++)
// p_pa is the load address of this segment (as well
// as the physical address)
readseg(ph->p_pa, ph->p_memsz, ph->p_offset);
// call the entry point from the ELF header
// note: does not return!
((void (*)(void)) (ELFHDR->e_entry))();
bad:
outw(0x8A00, 0x8A00);
outw(0x8A00, 0x8E00);
while (1)
/* do nothing */;
}
关于ELF和DWARF可以参考前面写的博客ELF文件及读取。
具体到如何读取ELF的段就不再介绍了,只是简单讲一下流程,实际上有很多库可以帮忙读取ELF文件。
- 这里先读取了ELF的头部信息,判断是否是一个合法的ELF文件
- 随后加载程序中的每一个段,从外存读入内存
ELFHDR + ELFHDR->e_phoff实际就是一个Proghdr类型数组的首地址。。。
ph->paddr根据参考文献中的说法指的是这个段在内存中的物理地址。ph->off字段指的是这段的开头相对于这个elf文件的开头的偏移量。ph->filesz字段指的是这个段在elf文件中的大小。ph->memsz则指的是这个段被实际装入内存后的大小。通常来说memsz一定大于等于filesz,因为段在文件中时许多未定义的变量并没有分配空间给它们。所以这个循环就是在把操作系统内核的各个段从外存读入内存中。
然后最后的:
((void (*)(void)) (ELFHDR->e_entry))();
就是进入内核程序的入口。
可以在反汇编(obj/boot/boot.asm)和gdb中看到ELFHDR->e_entry语句的执行以及对应的跳转的指令地址。
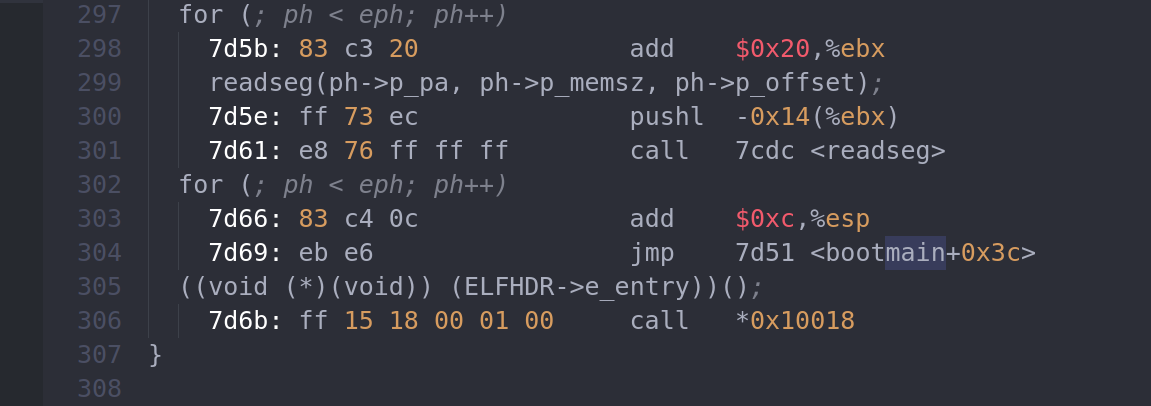
首先定位到指令地址是0x7d6b,然后用gdb打上断点:
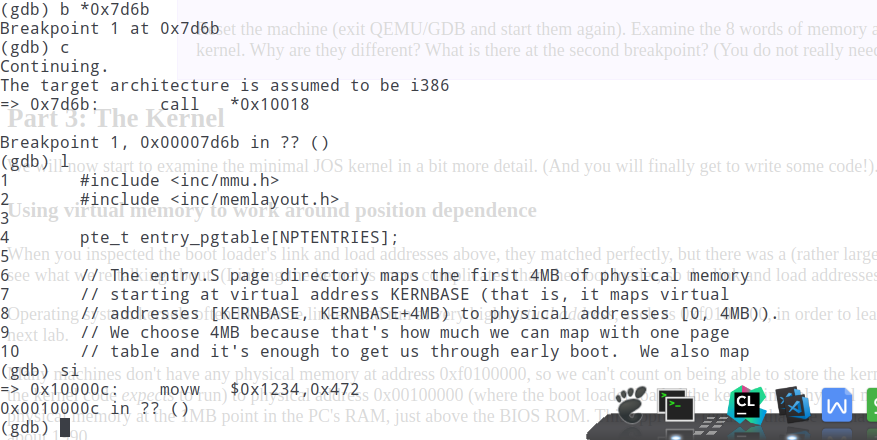
可以看到内核程序的入口地址就是*0x10018,但实际跳转的却是0x10000c,因为这里call的其实是0x10018这个地址存储的值,0x10018里存储的就是0x0010000c。

这个结果和readelf -h以及objdump -f的结果是一致的:
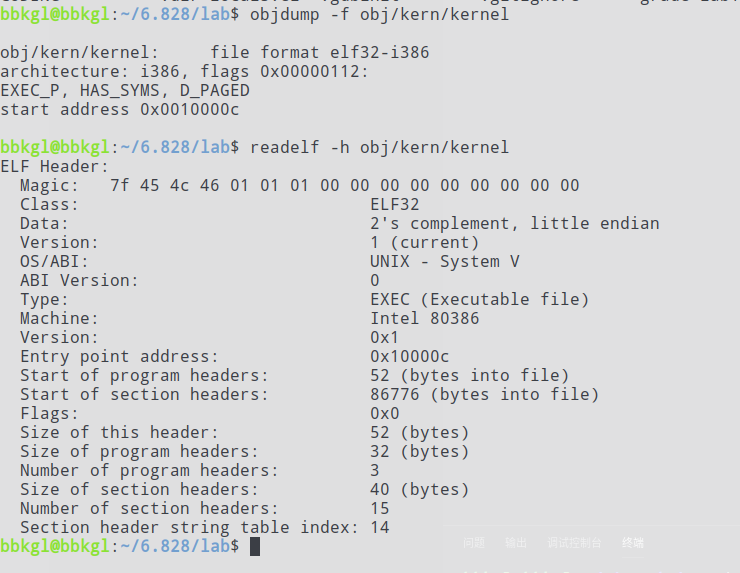
为什么会出现反汇编中call的地址与实际入口地址不一样的情况呢?
前面提到了保护模式中,CPU的寻址方式发生了变化。
Exercise 6 中提到:在BIOS进入Boot loader时检查内存的8个字在0x00100000处,然后在引导加载程序进入内核时再次检查。 他们为什么不同? 第二个断点有什么?
这个其实能想到了,因为这个时候kernel的代码段并没有加载进入到内存里,实际上应该是0。
GDB X用法
x/Ni:查看某个地址往后几个地址单位的内容,i表示地址格式。
-
x /8i 0x100000