故乡云水地
归梦不宜秋
继续接上文,分析UE GC的mark和sweep。
可达性分析
通过调用 FRealTimeGC::PerformReachabilityAnalysis() 实现对所有 UObject 的可达性分析。
void PerformReachabilityAnalysis(EObjectFlags KeepFlags, bool bForceSingleThreaded, bool bWithClusters)
{
/** Growing array of objects that require serialization */
FGCArrayStruct* ArrayStruct = FGCArrayPool::Get().GetArrayStructFromPool();
TArray<UObject*>& ObjectsToSerialize = ArrayStruct->ObjectsToSerialize;
// Reset object count.
GObjectCountDuringLastMarkPhase.Reset();
// Make sure GC referencer object is checked for references to other objects even if it resides in permanent object pool
if (FPlatformProperties::RequiresCookedData() && FGCObject::GGCObjectReferencer && GUObjectArray.IsDisregardForGC(FGCObject::GGCObjectReferencer))
{
ObjectsToSerialize.Add(FGCObject::GGCObjectReferencer);
}
{
const double StartTime = FPlatformTime::Seconds();
(this->*MarkObjectsFunctions[GetGCFunctionIndex(!bForceSingleThreaded, bWithClusters)])(ObjectsToSerialize, KeepFlags);
UE_LOG(LogGarbage, Verbose, TEXT("%f ms for MarkObjectsAsUnreachable Phase (%d Objects To Serialize)"), (FPlatformTime::Seconds() - StartTime) * 1000, ObjectsToSerialize.Num());
}
{
const double StartTime = FPlatformTime::Seconds();
PerformReachabilityAnalysisOnObjects(ArrayStruct, bForceSingleThreaded, bWithClusters);
UE_LOG(LogGarbage, Verbose, TEXT("%f ms for Reachability Analysis"), (FPlatformTime::Seconds() - StartTime) * 1000);
}
// Allowing external systems to add object roots. This can't be done through AddReferencedObjects
// because it may require tracing objects (via FGarbageCollectionTracer) multiple times
FCoreUObjectDelegates::TraceExternalRootsForReachabilityAnalysis.Broadcast(*this, KeepFlags, bForceSingleThreaded);
FGCArrayPool::Get().ReturnToPool(ArrayStruct);
#if UE_BUILD_DEBUG
FGCArrayPool::Get().CheckLeaks();
#endif
}
注意到定义了一个 FGCArrayStruct 类型的局部变量 ArrayStruct,用于存储需要序列化的 UObject。这个变量通过 FGCArrayPool::GetArrayStructFromPool() 返回,在 MarkObjectsAsUnreachable() 也可以见到这样的用法。 ArrayStruct->ObjectsToSerialize 是一个长度持续增长的序列,在整个可达性分析的过程中存储所有可达的UObject指针。我感觉是通过存在这样的一个序列池,内存连续,用于在可达性分析阶段存储 UObject 指针,以减小cache miss。
首先将 FGCObject::GGCObjectReferencer 加入到了 ObjectsToSerialize 中, FGCObject::GGCObjectReferencer 是类 FGCObject 中的一个静态成员,其充当了一座联系 FGCObject 和 UObject 的桥梁,可以让继承于 FGCObject 的对象,通过调用 AddReferencedObjects() 将自己纳入到可达性分析中。其实就是可以让 FGCObject 子类的一些 UObject 成员可以被可达性分析判定为可达,防止成员中的 UObject 被清理掉,所以会看到类 GGCObjectReferencer 中有一个 TArray<FGCObject *> 的成员,用于可达性分析中遍历每个 FGCObject 对象。这件事虽然说起来简单,但UE中实现却相当复杂。
后面两处代码块中,一处会遍历所有的 UObject,试图将它们都标记为不可达,明确可达或者特殊的UObject的放入到 ObjectsToSerialize 中,所以可以看到传的是引用。
另外一处就是可达性分析,可达性分析中会逐渐将所有可达的 UObject 添加到 ArrayStruct->ObjectsToSerialize 中,不可达的则标记不可达。
MarkObjectsAsUnreachable
FRealTimeGC::PerformReachabilityAnalysis() 中调用的是 *MarkObjectsFunctions[index],这里得到的是一个函数指针。
/** Default constructor, initializing all members. */
FRealtimeGC()
{
MarkObjectsFunctions[GetGCFunctionIndex(false, false)] = &FRealtimeGC::MarkObjectsAsUnreachable<false, false>;
MarkObjectsFunctions[GetGCFunctionIndex(true, false)] = &FRealtimeGC::MarkObjectsAsUnreachable<true, false>;
MarkObjectsFunctions[GetGCFunctionIndex(false, true)] = &FRealtimeGC::MarkObjectsAsUnreachable<false, true>;
MarkObjectsFunctions[GetGCFunctionIndex(true, true)] = &FRealtimeGC::MarkObjectsAsUnreachable<true, true>;
...
}
通过对非类型参数的函数模板 MarkObjectsAsUnreachable 实例化得到具体函数的指针,将函数指针的地址存储到 MarkObjectsFunctions 数组中,就得到了四种情况下的 MarkObjectsAsUnreachable() 函数,也就是 是否多线程和是否使用Cluster的组合。
template <bool bParallel, bool bWithClusters>
void MarkObjectsAsUnreachable(TArray<UObject*>& ObjectsToSerialize, const EObjectFlags KeepFlags)
{
...
}
函数内部代码比较长,就不放代码一行一行分析了,介绍下重要流程。
函数功能:按照既定规则,将 UObject 加入到 ObjectsToSerializeArrays 中或者标记为 Unreachable 不可达,也就是认为可达的 UObject 都添加到了 ObjectsToSerializeArrays 中。
认为可达的 UObject 符合以下条件之一:
- 属于 root set
- 包含
EInternalObjectFlags::GarbageCollectionKeepFlags - 不在 pending kill 状态,且包含
KeepFlags,且KeepFlags != 0
当然除此之外还有Cluster的处理,这不是重点。过程使用了 UE 的多线程框架并行处理和标记,详见 ParallelFor。
最终在可达性分析之前得到了部分可达对象序列 ObjectsToSerializeArrays。
PerformReachabilityAnalysisOnObjects
实际调用链条为:
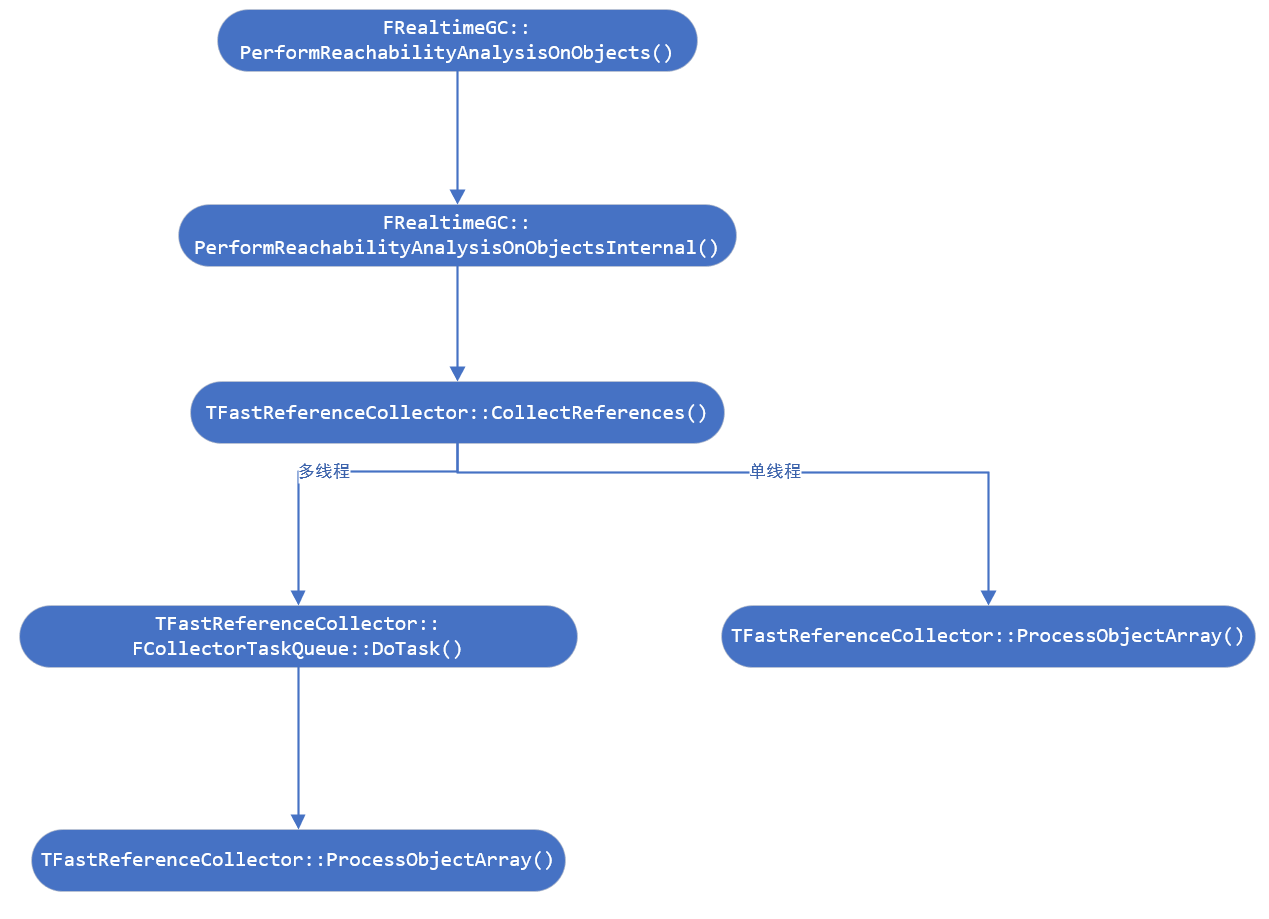
也是根据是否使用多线程来决定调用路径的,如果是多线程就会用到类 TFastReferenceCollector::FCollectorTaskQueue 的多线程并行机制。
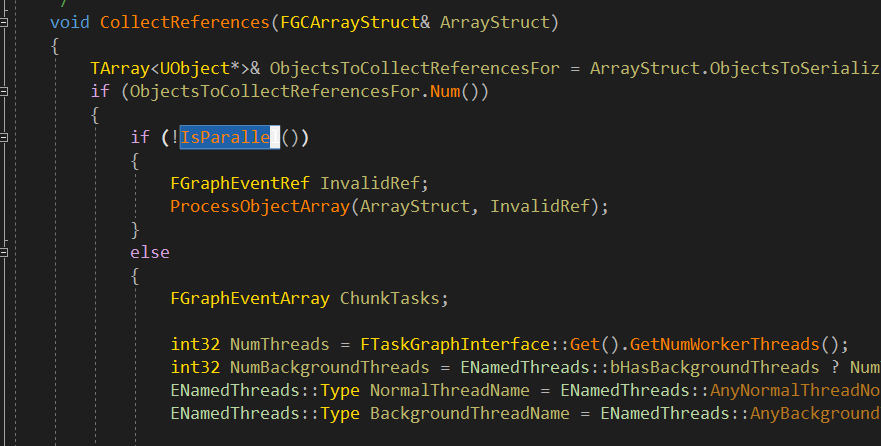
不过最终都会调用到 TFastReferenceCollector::ProcessObjectArray() 这个函数,多线程则是将 可达的UObject 序列分到不同的线程执行可达性分析。这种情况下,性能就取决于最慢的那个线程了。当然还有个问题,就是线程同步的成本会不会也相当大呢?暂时挖坑,以后分析UE的多线程相关的实现。
以下分析 ProcessObjectArray() 的实现,这个函数的实现并不在 GarbageCollection.cpp 中,而是在 FastReferenceCollection.h 中。
简单描述该函数的功能:通过遍历ObjectsToSerialize,进行广度搜索(部分类型会深度有限搜索),将可达的UObject指针不断添加到ObjectsToSerialize中,直到ObjectsToSerialize中所有的UObject都被访问过。这样就将可达的UObject对象全部收集好了,未收集的即为不可达。
看到定义了一个Stack时,我以为会使用栈模拟递归深搜来收集UObject,但实际上只有部分类型才会模拟递归,否则的话就直接加入到NewObjectsToSerialize中,像是广度优先搜索和深度优先搜索结合。

其中遍历完当前的 ObjectsToSerialize 后,一轮遍历就完成了。顺利的话,就会将 NewObjectsToSerialize 和 ObjectsToSerialize 进行交换,下一轮中就会遍历 “原NewObjectsToSerialize”,往 “原ObjectsToSerialize” 中添加元素。
而如果 NewObjectsToSerialize 数量大于一个Task可以处理的数量,就会将 NewObjectsToSerialize 再次分给1到多个线程去遍历。
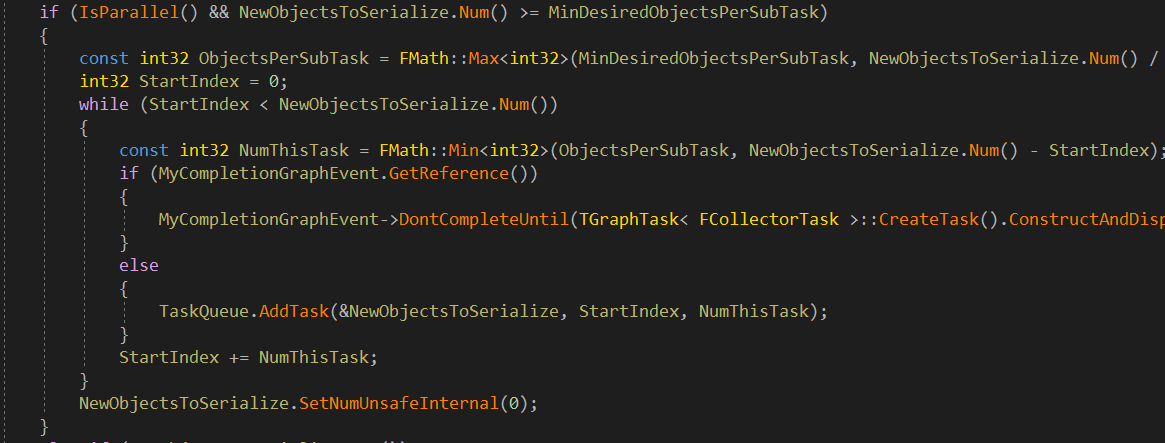
对于每个UObject,会遍历其对应的 TokenStream ,也就是 GC信息收集 中介绍的引用收集得到的序列。然后通过偏移量访问到每个UObject的子UObject,判断其类型。类型处理主要分为三种:
- 一种就是普通的UObject,这种情况下就直接将子UObject添加到
NewObjectsToSerialize中,不继续递归处理,同时为其添加到引用。 - 第二种就是ArrayStruct类型,这种情况下会递归扫描序列中的UObject。
- 还有就是需要调用
AddReferencedObjects添加引用的,这个在前面提到过
array/struct类型的处理,也可以在函数前面部分的for循环看到。
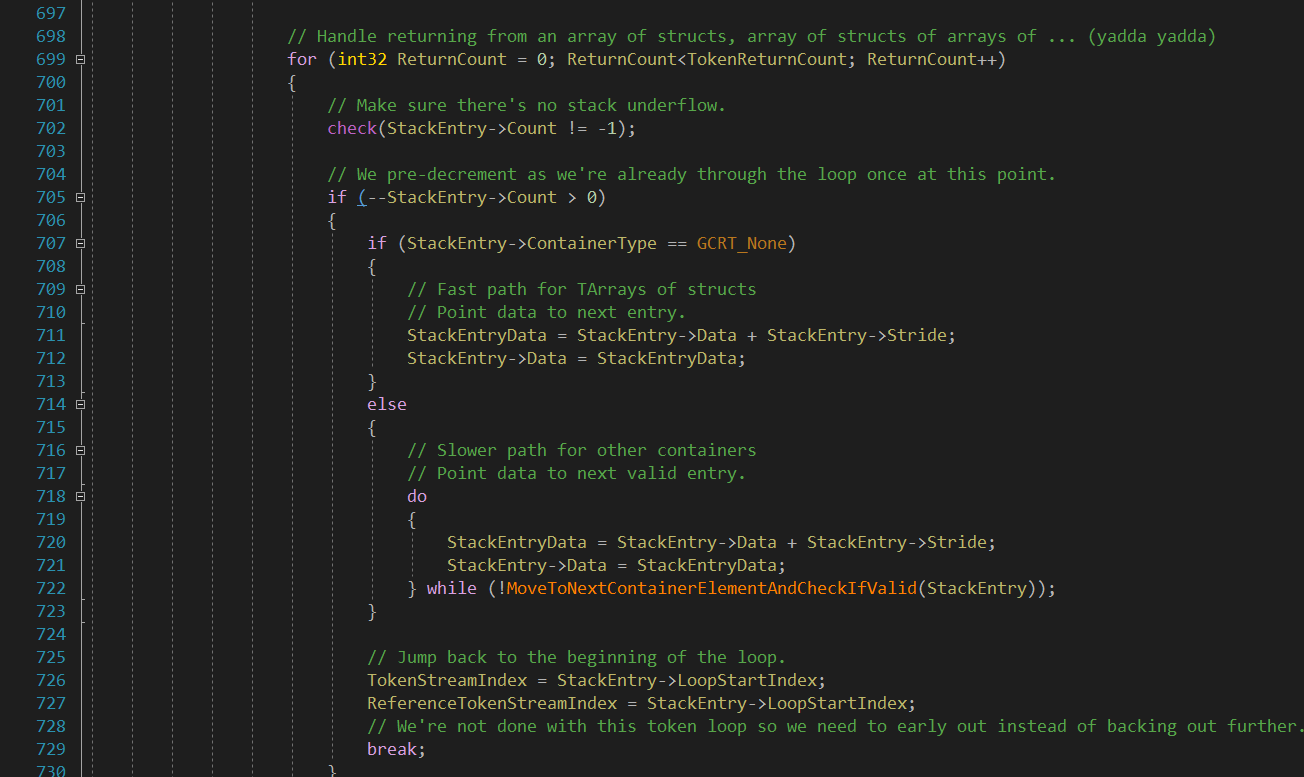
最终每个可达的UObject都会在函数 HandleObjectReference() 中处理,清除掉不可达标记,如果是多线程,则需要通过原子操作判断是否已经清除过,过程不再赘述。
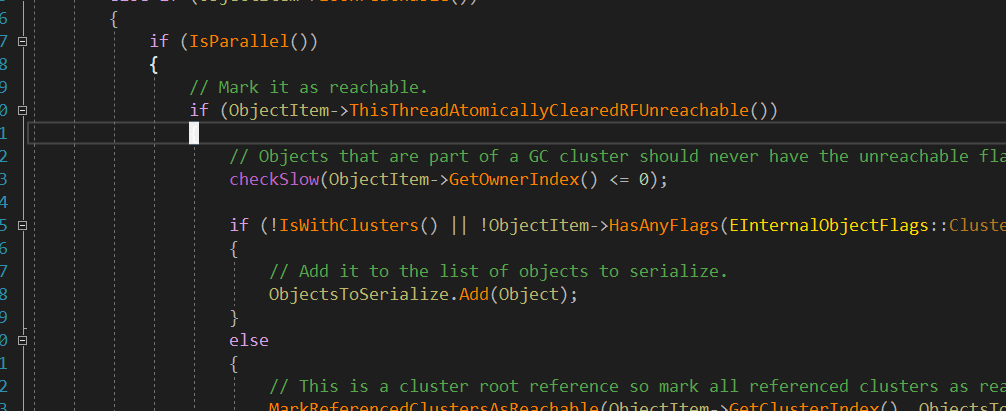
这里还有个疑问,被 UPROPERTY 修饰的成员,如果被 GC 回收了,如何将对应的指针置空的呢?
很容易想到,既然可达性分析的时候会遍历所有引用,也就是能拿到每个成员的偏移量和实际的虚拟内存地址,这样情况下,将对应的地址上8(64bit)字节的内容直接置为0就可以了。当然这种方法相当暴力,UE4是直接传了一个指针的引用,这样的话就能修改指针的指向了,具体的实现在 HandleObjectReference() 中,可以看到参数Object是个指针类型的引用,自然可以修改指针的指向,其实就是修改指针记录的地址。
FORCEINLINE void HandleObjectReference(TArray<UObject*>& ObjectsToSerialize, const UObject * const ReferencingObject, UObject*& Object, const bool bAllowReferenceElimination)
{
...
const int32 ObjectIndex = GUObjectArray.ObjectToIndex(Object);
FUObjectItem* ObjectItem = GUObjectArray.IndexToObjectUnsafeForGC(ObjectIndex);
// Remove references to pending kill objects if we're allowed to do so.
if (ObjectItem->IsPendingKill() && bAllowReferenceElimination)
{
//checkSlow(ObjectItem->HasAnyFlags(EInternalObjectFlags::ClusterRoot) == false);
checkSlow(ObjectItem->GetOwnerIndex() <= 0)
// Null out reference.
Object = NULL;
}
收集不可达对象
收集不可达对象的操作在函数 GatherUnreachableObjects 中执行。里面有Cluster的解组操作,但这篇文章不对这个展开讲。
函数的主要功能:(并行)遍历 GUObjectArray ,将所有标记为不可达的UObject加入到 GUnreachableObjects 中。
从源码中看出来,这个过程是直接访问的 GUObjectArray ,这样确实需要加锁,GameThread必须等待这个过程完成,否则可能会访问冲突。不过我在想,如果在前面过程中将所有标记不可达的时候就复制一份,因为全部是指针,直接memcopy。这样后续清理包括这个收集过程不就不需要再去访问这个 GUObjectArray 了吗,然后再分帧一同清理掉。进一步可以做成双Buffer,这样就每次swap一下就行。
不可达对象清理
从我卑微又弱小的角度来看,清理过程应该就是几行代码:
for (auto &objectPtr : unreachableList) {
delete objectPtr;
}
但是UE里的实现却较为复杂,我想至少应该考虑以下几个方面:
- 分帧清理降低性能影响
- 多线程加速
- Cluster(簇)
- 清理
UObjectHashTables等全局的UObject表以及其他引用
可达性分析的标记过程结束后,便会将所有不可达对象收集起来,在清理阶段调用 IncrementalPurgeGarbage() 函数执行真正的清理过程。
IncrementalPurgeGarbage
前面已经说到了,清理过程不一定是分帧增量的,仅在 ConditionalCollectGarbage() 中调用时才会执行分帧清理,否则全部为全量清理。且Editor下一定是全量清理,因为mark结束后就会直接全量清理,所以后续Tick中都不会执行 ConditionalCollectGarbage()。
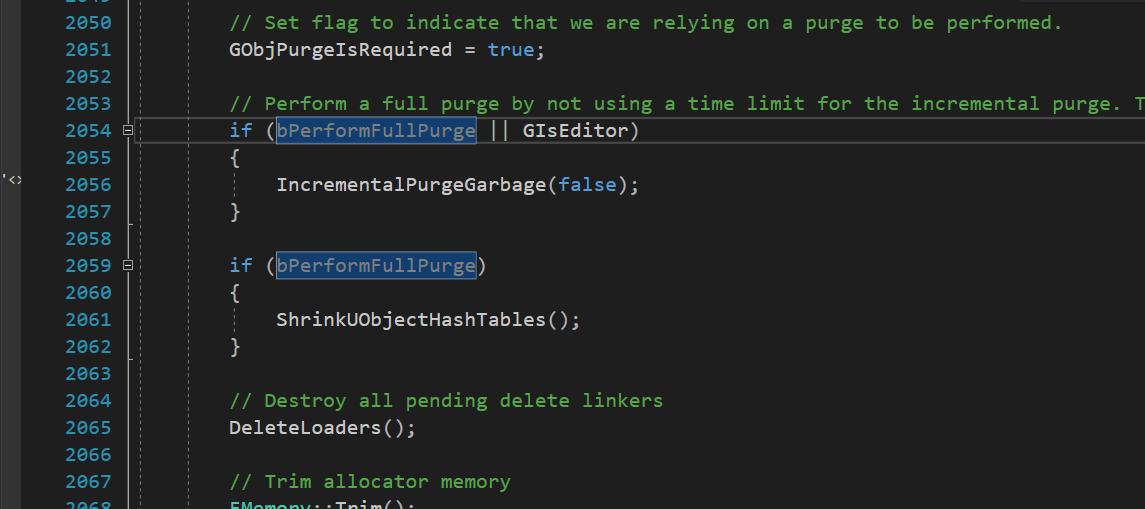
函数源码中,如果之前已经全部清理完成,则进入 IncrementalPurgeGarbage() 后会立刻return。
void IncrementalPurgeGarbage(bool bUseTimeLimit, float TimeLimit)
{
...
// Early out if there is nothing to do.
if (!GObjPurgeIsRequired)
{
return;
}
...
}
确定执行清理后,代码中会定义一个临时的 FResetPurgeProgress 结构体 ResetPurgeProgress。
struct FResetPurgeProgress
{
bool& bCompletedRef;
FResetPurgeProgress(bool& bInCompletedRef)
: bCompletedRef(bInCompletedRef)
{
// Incremental purge is now in progress.
GObjIncrementalPurgeIsInProgress = true;
FPlatformMisc::MemoryBarrier();
}
~FResetPurgeProgress()
{
if (bCompletedRef)
{
GObjIncrementalPurgeIsInProgress = false;
FPlatformMisc::MemoryBarrier();
}
}
} ResetPurgeProgress(bCompleted);
显然这是个局部变量,利用栈变量的生命周期进行某些初始化和”反初始化“。在构造函数中标识清理过程开始执行,并通过内存屏障保证标识动作完成,在析构函数中进行标识的逆操作。这种类似于 RAII 的资源管理方式在UE4中大量使用,同时 static 懒加载也大量被使用。
紧接着就会调用 UnhashUnreachableObjects() 函数执行真正的 UObject 清理。
{
// Lock before settting GCStartTime as it could be slow to lock if async loading is in progress
// but we still want to perform some GC work otherwise we'd be keeping objects in memory for a long time
FConditionalGCLock ScopedGCLock;
// Keep track of start time to enforce time limit unless bForceFullPurge is true;
GCStartTime = FPlatformTime::Seconds();
bool bTimeLimitReached = false;
if (GUnrechableObjectIndex < GUnreachableObjects.Num())
{
bTimeLimitReached = UnhashUnreachableObjects(bUseTimeLimit, TimeLimit);
if (GUnrechableObjectIndex >= GUnreachableObjects.Num())
{
FScopedCBDProfile::DumpProfile();
}
}
if (!bTimeLimitReached)
{
bCompleted = IncrementalDestroyGarbage(bUseTimeLimit, TimeLimit);
}
}
上面这段代码里虽然显式调用了 FConditionalGCLock 的构造函数试图获取GC锁,但并不是像之前的会等待获取到锁才执行 scope 里的逻辑。这里如果没拿到锁也会继续执行,不会等,也不会退出函数。
/** Locks GC within a scope but only if it hasn't been locked already */
struct FConditionalGCLock
{
bool bNeedsUnlock;
FConditionalGCLock()
: bNeedsUnlock(false)
{
if (!FGCCSyncObject::Get().IsGCLocked())
{
AcquireGCLock();
bNeedsUnlock = true;
}
}
~FConditionalGCLock()
{
if (bNeedsUnlock)
{
ReleaseGCLock();
}
}
};
GUnrechableObjectIndex 是一个全局的index,会记录下一个要被的 UObject 下标,主要用于增量清理时下一次清理可以接上次的进度继续执行。
在GC所的Scope内主要执行两个逻辑:
UnhashUnreachableObjects(),该函数内会调用每个UObject对象的ConditionalBeginDestroy()函数,使用GUnrechableObjectIndex记录下一个要调用ConditionalBeginDestroy()的UObject的下标,最终会调用到BeginDestroy()函数;IncrementalDestroyGarbage(),该函数内部会调用每个UObject对象的ConditionalFinishDestroy()函数,使用GObjCurrentPurgeObjectIndex记录下一个要调用ConditionalFinishDestroy()的UObject的下标,最终会调用到FinishDestroy()函数
为什么要分这两个步骤呢?
其实 BeginDestroy() 更像是对清理流程的通知,让UObject需要在其他线程进行的清理工作启动,异步清理结束后,FinishDestroy() 才能被调用。调用FinishDestroy() 前,先判断UObject自己的清理工作是否已经完成,否则会保存到列表 GGCObjectsPendingDestruction 里。后续会继续尝试调用 GGCObjectsPendingDestruction 中每个 UObject 的FinishDestroy() 。
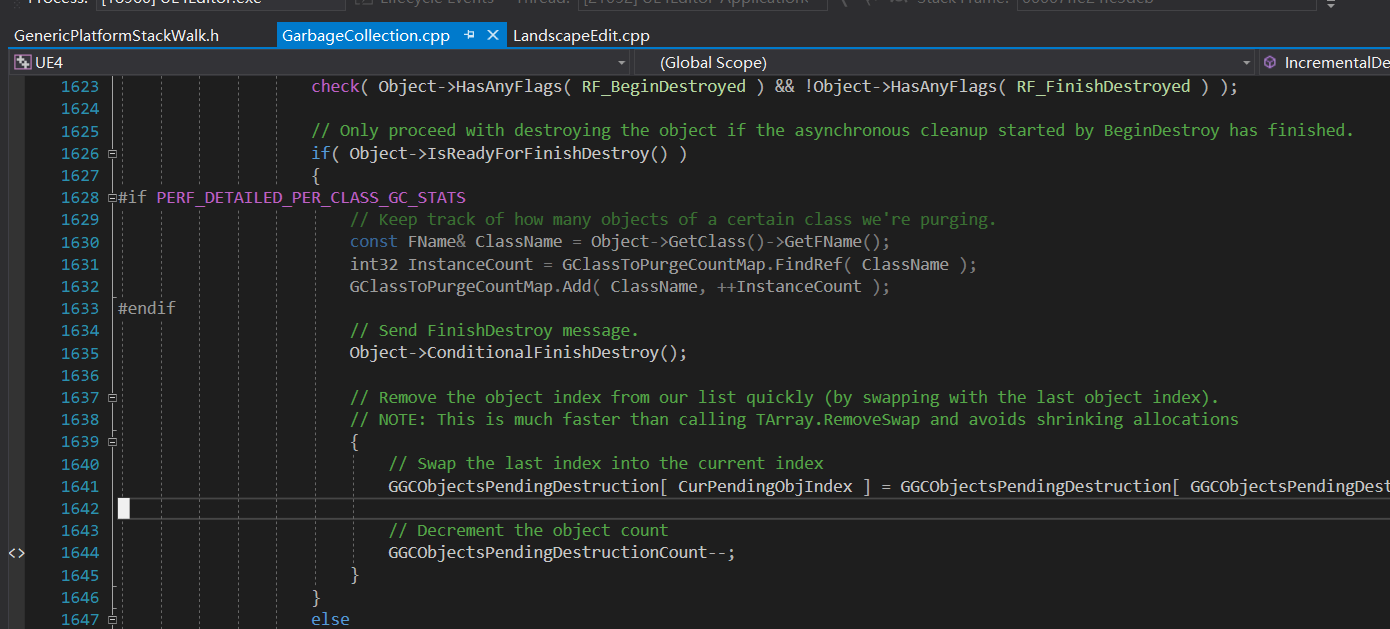
第二次尝试调用 FinishDestroy() 有两种情况:
- 如果是分帧清理,则遍历
GGCObjectsPendingDestructionCount调用FinishDestroy()的操作会留到下帧再执行; - 如果是全量清理,则直接遍历
GGCObjectsPendingDestructionCount,对每个 UObject 等待其异步清理工作完成,最终调用FinishDestroy(),一般是等待渲染线程完成。
这里其实能看出来,无论是 BeginDestroy() 还是 FinishDestroy() 其实都是一种通知机制,不是真正执行清理逻辑。执行 FinishDestroy() ,就到了调用析构函数,释放内存的部分了。
详细的逻辑可以在 TickDestroyGameThreadObjects() 中找到,依然会根据 bUseTimeLimit 判断是否要分帧清理。
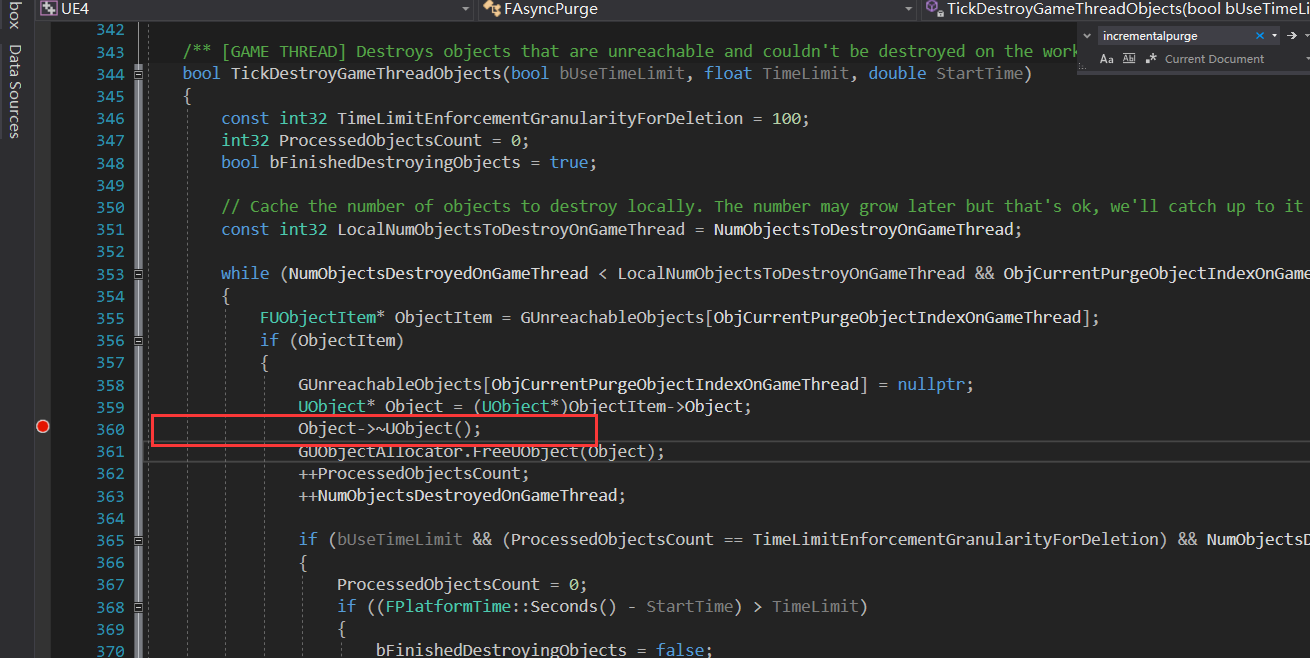
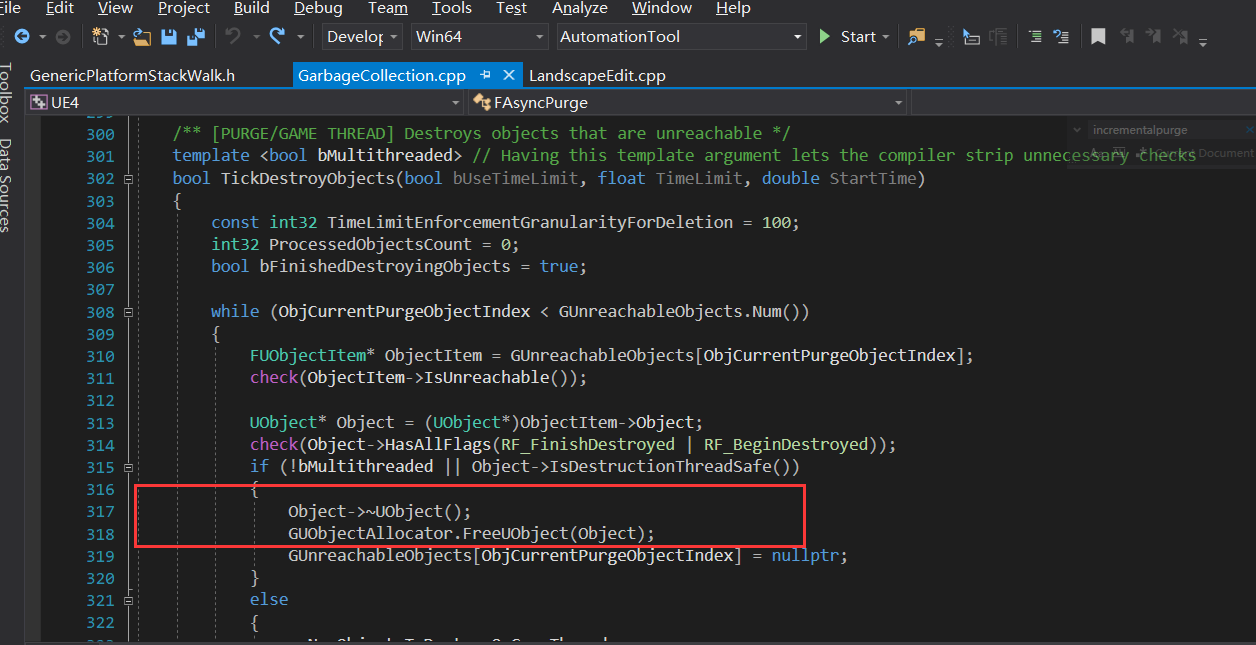
最终每个UObject都会在这两个地方调用析构函数,值得注意的是,这部分逻辑可能会在GameThread中执行,也可能在异步线程中执行,具体会在生成 FAsyncPurge 对象的时候就决定好。
至此,mark 和 sweep就都介绍完了。